Scikit-Learn#
Learning Objectives#
Learn how to import and use Scikit-Learn in Python
Understand the basic concepts and purpose of Scikit-Learn in machine learning tasks
Implement linear regression, k-means clustering, and decision tree models using Scikit-Learn
Understand the applications and limitations of each model
Learn how to clean and preprocess data using Pandas before feeding it into machine-learning models
Understand the importance of handling missing values and feature engineering
Learn how to evaluate the performance of different machine-learning models
Interpret the output of models to make informed decisions based on the data
Download Files#
Leed Air Pollution Monitoring Station 2023 Complete Dataset.Csv
# import the packages used before and read in the required data
import pandas as pd
import matplotlib.pyplot as plt
air_pollution_data_2023_complete_dataset = pd.read_csv("data/LEED_air_pollution_monitoring_station_2023_complete_dataset.csv", index_col=0)
air_pollution_data_2023_complete_dataset = air_pollution_data_2023_complete_dataset.dropna()
# scikit learn can be imported with the the following command
import sklearn
What is Scikit-Learn?#
Scikit-Learn is a popular Python package that provides a set of algorithms and tools for machine learning that are both easy to use and effective. The package includes support for various tasks, including classification, regression, clustering, dimensionality reduction and model selection and normalization.
In Scikit-Learn, the models that are available include a massive number of possible arguments, and so for the purpose of this course, the default arguments have been used.
air_pollution_data_2023_complete_dataset["date"] = pd.to_datetime(air_pollution_data_2023_complete_dataset["date"], format="%d/%m/%Y %H:%M")
air_pollution_data_2023_complete_dataset["Hour"] = air_pollution_data_2023_complete_dataset["date"].dt.hour
display(air_pollution_data_2023_complete_dataset.head())
| date | NO2 | O3 | NO | Wind Speed | Temperature | site | Year | Hour | |
|---|---|---|---|---|---|---|---|---|---|
| 24664 | 2023-01-01 01:00:00 | 7.30306 | 76.61852 | 1.22702 | 4.9 | 7.2 | Leeds Centre | 2023.0 | 1 |
| 24665 | 2023-01-01 02:00:00 | 4.31351 | 79.67418 | 0.82507 | 7.0 | 7.5 | Leeds Centre | 2023.0 | 2 |
| 24666 | 2023-01-01 03:00:00 | 2.95539 | 81.50758 | 0.79333 | 7.3 | 7.3 | Leeds Centre | 2023.0 | 3 |
| 24667 | 2023-01-01 04:00:00 | 2.08340 | 81.45519 | 0.53947 | 7.2 | 7.2 | Leeds Centre | 2023.0 | 4 |
| 24669 | 2023-01-01 06:00:00 | 2.95643 | 82.71238 | 0.57120 | 6.8 | 7.1 | Leeds Centre | 2023.0 | 6 |
Linear Regression#
Linear regression is a simple model that is able to predict a dependent variable based on one or more independent variables, with the assumption of a linear relationship between the two.
from sklearn.linear_model import LinearRegression
import numpy as np
# Create some simple data
X = air_pollution_data_2023_complete_dataset[["Wind Speed"]]
y = air_pollution_data_2023_complete_dataset[["NO2"]]
# Train a linear regression model
model = LinearRegression()
model.fit(X, y)
# Plotting the data points
plt.scatter(X, y, color='blue', label='Observations', alpha=0.05)
# Predicting the values to draw the regression line
# We use minimum and maximum values of X to cover the whole range of data
X_new = np.linspace(X.min(), X.max(), 100).reshape(-1, 1) # Making it a column vector
y_predict = model.predict(X_new)
# Plotting the regression line
plt.plot(X_new, y_predict, color='red', linewidth=2, label='Regression Line')
# Adding title and labels
plt.title('Relationship Between Wind Speed and NO$_2$ Levels')
plt.xlabel('Wind Speed m/s')
plt.ylabel('NO$_2$ Concentration')
plt.legend()
# Show the plot
plt.show()
# Extracting and printing the intercept and slope
intercept = model.intercept_
slope = model.coef_
print("Intercept of the regression line:", intercept[0]) # Intercept is usually an array with a single element
print("Slope of the regression line:", slope[0][0]) # Slope is an array of arrays, each containing one element per feature
/home/runner/.cache/pypoetry/virtualenvs/coding_for_reproducible_research_courses-l5b2FSBI-py3.11/lib/python3.11/site-packages/sklearn/utils/validation.py:2827: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names
warnings.warn(
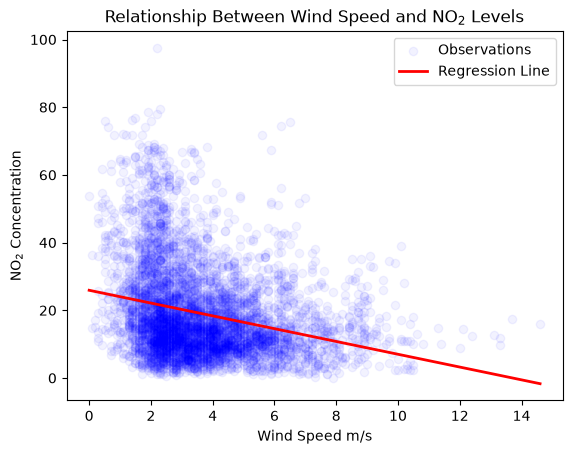
Intercept of the regression line: 25.914968461312014
Slope of the regression line: -1.8904584011012917
K-Means Clustering#
K-means clustering is a method for partitioning data into a specified number of clusters by minimizing the variance within each cluster.
from sklearn.cluster import KMeans
import numpy as np
# Set the number of clusters
k = 3 # Example number of clusters
# Create KMeans model
kmeans = KMeans(n_clusters=k, random_state=0)
# Fit the model
clusters = kmeans.fit_predict(air_pollution_data_2023_complete_dataset[['NO2', 'Temperature']])
# Assuming 'clusters' has been added to your DataFrame
air_pollution_data_2023_complete_dataset['cluster'] = clusters
# Define a list of colors or use a colormap with discrete colors
colors = plt.cm.get_cmap('tab10', len(air_pollution_data_2023_complete_dataset['cluster'].unique())) # 'tab10' supports up to 10 unique categories
# Plotting clusters categorically
plt.figure(figsize=(10, 6))
scatter = plt.scatter(air_pollution_data_2023_complete_dataset['NO2'], air_pollution_data_2023_complete_dataset['Wind Speed'],
c=air_pollution_data_2023_complete_dataset['cluster'], cmap=colors, alpha=0.5)
plt.title('Clusters of Air Pollution Data')
plt.xlabel('NO2 Concentration')
plt.ylabel('Wind Speed') # Adjusted to match the y-axis label with your data
# Create a legend for clusters
# Create handles and labels for the legend
handles, labels = scatter.legend_elements(prop='colors')
plt.legend(handles, labels, title="Clusters")
plt.show()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[8], line 5
1 # Assuming 'clusters' has been added to your DataFrame
2 air_pollution_data_2023_complete_dataset['cluster'] = clusters
3
4 # Define a list of colors or use a colormap with discrete colors
----> 5 colors = plt.cm.get_cmap('tab10', len(air_pollution_data_2023_complete_dataset['cluster'].unique())) # 'tab10' supports up to 10 unique categories
6
7 # Plotting clusters categorically
8 plt.figure(figsize=(10, 6))
AttributeError: module 'matplotlib.cm' has no attribute 'get_cmap'
Decision Tree Models#
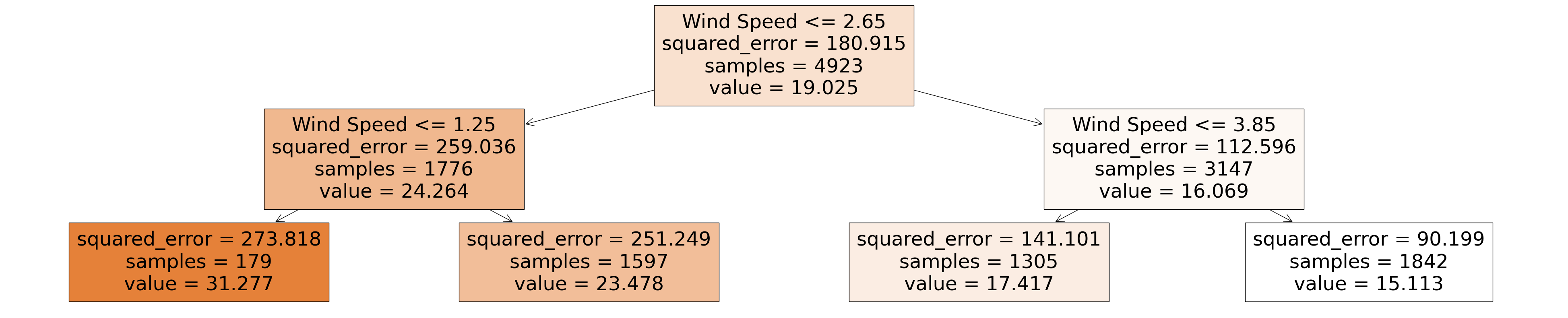
Decision Trees are a model framework that splits data into branches based on the some input data - in our case wind speed. The model resembles a tree structure with decision points and leaf nodes where each decision leads to further splits, eventually ending on a final prediction based on the input features.
from sklearn.tree import DecisionTreeRegressor
# Initialize the model
decision_tree_regressor = DecisionTreeRegressor(random_state=42, max_depth=2)
# Train the model on the entire dataset
decision_tree_regressor.fit(air_pollution_data_2023_complete_dataset[["Wind Speed"]], air_pollution_data_2023_complete_dataset["NO2"])
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# Plot the decision tree
plt.figure(figsize=(50,10))
plot_tree(decision_tree_regressor, feature_names=['Wind Speed'], filled=True)
plt.show()
Further Models#
This section of the course has only introduced a very small subset of models that are avaliable, alongside not diving into the different arguments that are available. If you are interested in learning more about the models themselves, and key practical aspects of deploying and ensuring the validity of models you develop, then please attend e course “Introduction to Machine Learning”.