Understanding GPUs, CPUs, and Compilers#
Learning Objectives#
By the end of this section, learners will be able to:
Explain the fundamental differences between CPUs and GPUs, including their architecture, core design, and typical use cases.
Describe the key characteristics of GPUs, such as parallelism, throughput orientation, FLOPs, and memory architecture.
Compare the strengths and limitations of CPUs and GPUs, identifying which types of tasks are best suited to each.
Recognize common pitfalls and considerations when using GPUs, such as data transfer overhead and parallelisation constraints.
Define what a compiler is and explain its role in translating high-level code into machine-executable instructions.
Distinguish between CPU and GPU compilers, including examples such as
gcc,clang, and NVIDIA’snvcc.Appreciate the importance of compilers in high-performance computing and GPU programming, particularly for optimising performance and ensuring compatibility.
Understand how CPUs and GPUs collaborate in accelerated computing, and why balancing their roles is crucial for efficiency.
Overview#
Before going deeper into GPU programming, it’s essential to understand some fundamental concepts:
What exactly is a GPU, and how does it differ from a CPU?
What is a compiler, and why do we care about compilers in the context of running code on CPUs/GPUs?
What is a GPU?#
GPU stands for Graphics Processing Unit. Historically, GPUs were specialised processors designed to handle graphics rendering (for example, drawing images to your screen and handling 3D game visuals).

Fig. 1 GPUs were originally used to render 3D visuals on computer displays.#
Modern GPUs, especially those by NVIDIA, AMD, etc., are extremely powerful processors capable of general-purpose computing, not just graphics.
Key characteristics of a GPU
Many Cores: A GPU contains hundreds or thousands of smaller cores (processing units) that can perform calculations simultaneously. This makes GPUs excel at parallel processing. For example, an NVIDIA CUDA-enabled GPU might have thousands of threads running in parallel, which is excellent for tasks like matrix operations where the same operation is applied to many data points at once (originally for pixels on a screen).
Highly Throughput-Oriented: Each GPU core is relatively simpler and slower (in terms of single-thread performance) than a CPU core. However, because there are so many working in parallel, the GPU can achieve much higher throughput for suitable tasks (like processing millions of pixels or multiplying large matrices).
For example, consider:
A single 4K frame is 3840 × 2160 pixels = 8.29 million pixels.
Assume one pixel operation takes:
CPU: 0.05 μs
GPU: 0.20 μs
Serial time:
CPU:
8.29M × 0.05 μs = 0.415 sGPU:
8.29M × 0.20 μs = 1.66 s
A CPU has 4 cores
A GPU has 2048 cores
Parallel time:
CPU:
0.415 s ÷ 4 ≈ 0.1 sGPU:
1.66 s ÷ 2048 ≈ 0.00081 s
Output:
CPU: ~10 frames per second
GPU: ~1233 frames per second

Fig. 2 GPU processing: the frame is split into 2048 regions, with each GPU core handling a small portion simultaneously.#

Fig. 3 CPU processing: the frame is split into 4 regions, with each CPU core handling one large section.#
FLOPs (Floating-Point Operations per second): Another important measure of GPU performance is the number of floating-point operations it can perform.
Definition of a FLOP
One floating-point arithmetic operation (e.g., addition, multiplication)
A single unit of work in scientific or machine learning code
Throughput
FLOPS = FLOPs per second
1 GFLOP/s = 10^9 FLOPs per second
1 TFLOP/s = 10^12 FLOPs per second
This metric helps compare the raw computational power of GPUs (and CPUs) for workloads that rely heavily on floating-point calculations, such as simulations, deep learning, and scientific computing.
Use Case: GPUs are ideal for workloads that can be parallelised, such as graphics, linear algebra (which underpins machine learning, simulations etc.), image and signal processing. If you can break a task into many independent pieces, a GPU can often compute all those pieces faster than a CPU by doing them at the same time.
Memory Architecture: GPUs have their own memory (often called VRAM or device memory). This memory is separate from the system RAM that the CPU uses. Data needs to be transferred to GPU memory before the GPU can operate on it and back to the system RAM after, which is a crucial consideration, as these memory transfers can commonly be a bottleneck.
In summary, a GPU is a processor designed for parallel workloads, originally graphics, but now used for general computation via frameworks like CUDA, OpenCL and others. When you hear about “accelerating code with GPUs”, it usually involves finding the parts of a computation that can be done quickly in parallel (like applying the same operation to many elements) and offloading them to the GPU.
How is a GPU different from a CPU?#
CPU stands for Central Processing Unit. It’s the primary processor in your computer (the “brain” of the computer), which handles general-purpose tasks and runs the operating system, etc.
Key characteristics of a CPU:
Fewer, More Powerful Cores: A typical CPU might have 4 to 16 cores for a desktop or laptop or maybe up to a few dozen in a server. Each CPU core is very powerful in a single-thread performance sense. It has a high clock speed, sophisticated caching, and can execute complex sequences of instructions very quickly. CPUs excel at sequential processing and tasks that require a lot of logic or that cannot be massively parallelised.
General Purpose: CPUs are very flexible. They can handle everything from running your web browser to doing complex database operations. They have large caches, can branch (if/else logic) very efficiently, and handle a wide variety of workloads.
Memory and I/O: CPUs directly access system RAM and have sophisticated memory hierarchies (L1, L2, L3 caches) to speed up memory access. They also handle input/output (I/O) operations (reading disk, network, etc.) and coordinate with the rest of the system.
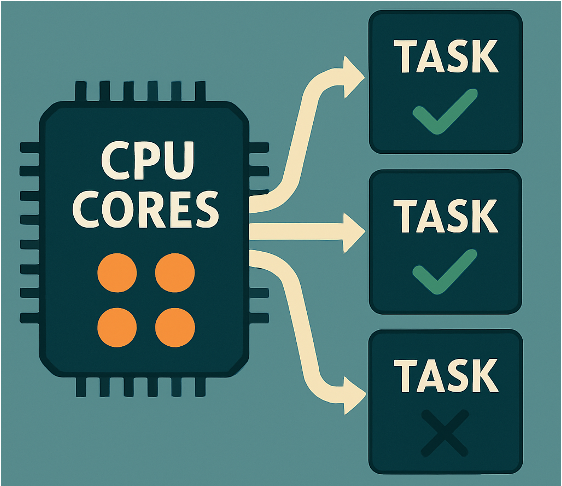
Fig. 4 CPUs excel at fewer, diverse tasks where each thread may follow its own, unpredictable path through the code.#
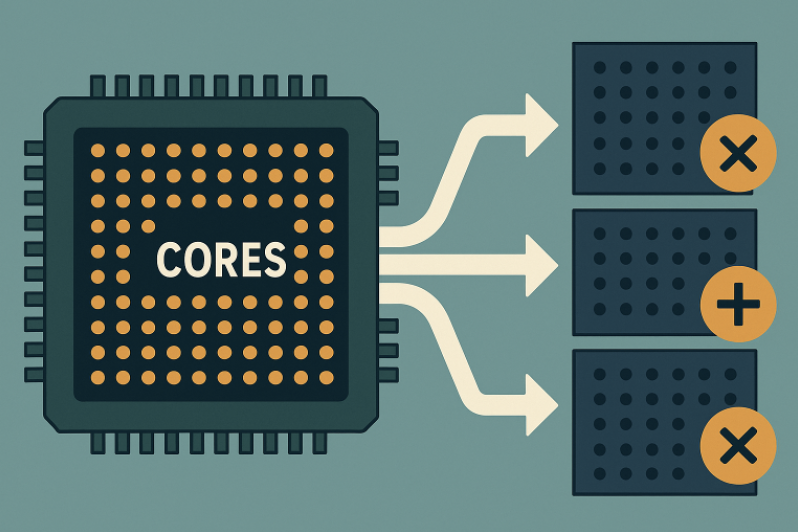
Fig. 5 GPUs shine when you can split your problem into lots of identical, independent pieces and process them simultaneously.#
CPU vs GPU#
It might be helpful to think of a CPU core like a skilled craftsman and a GPU like a factory with many workers:
If you have a task that requires intricate steps and must be done by one person, the craftsman (CPU) will do it efficiently.
Suppose you have a task that can be broken into 1000 simple, identical steps (like assembling simple parts). In that Case, a factory with 1000 workers (GPU cores) will do all those in parallel much faster than the single craftsman could, even if each worker is not as individually skilled as the craftsman.
When to use CPUs vs GPUs:#
Use CPU for tasks that are sequential or have a lot of conditional logic (e.g. running the operating system, complex decision-making code, and tasks that don’t repeat the same operation millions of times).
Use GPU for tasks that involve large data parallelism (e.g. vectorised math on large arrays, graphics rendering, machine learning training, etc.) In code, if you find yourself applying the same computation on every element of a large array or image, that is a good hint it could benefit from a GPU.
Note
Not all problems benefit from GPUs. Some tasks can’t be easily parallelised, and these will see little gain from a GPU and may even run slower if the offloading overhead is high. A classic example is a loop that has dependencies between iterations (each step depends on the previous one’s result). Such a loop is inherently sequential and won’t speed up on a GPU. In some cases, the algorithm may be better or worse than another for the same problem.
Pitfalls and Considerations#
Even if a task can run on a GPU, there are some considerations:
Data Transfer Overhead: Moving data between CPU (host) memory and GPU (device) memory and back takes time. For smaller tasks, this overhead can outweigh the GPU’s speed advantage.
Parallel Overhead: Launching kernel (GPU functions) has overhead. If you launch millions of very tiny GPU tasks, the overhead may become significant.
Precision and Hardware Constraints: Some GPUs (especially older ones) might be less predictive for double-precision arithmetic than CPUs or might not support certain features.
Despite these considerations, GPUs are a common piece of hardware for performance-critical software for a lot of scientific and data-intensive applications in the 2020s.
What is a Compiler?#
A compiler is a program that translates code from a high-level programming language (like C, C++ or Fortran) into low-level machine code (binary instructions) that a CPU (or GPU) can execute.
Why is this important?#
Computers ultimately only understand machine code (ones and zeros corresponding to instructions like “add these two registers”). As humans, we write in more abstract languages. The compiler is what bridges this gap. A good compiler also optimises code during this translation. It can rearrange instructions, eliminate redundancies, and use specialised CPU/GPU instructions to make the final program run faster.
Compilers in a CPU vs GPU context#
For CPU code, you might use compilers like gcc (GNU Compiler Collection for C/C++), clang or Intel ICC. For GPU code, if using NVIDIA GPUs, a common compiler is NVCC (NVIDIA’s CUDA Compiler), which compiles CUDA C++ code into GPU machine code (called PTX (Parallel Thread Execution) for NVIDIA architectures). Other frameworks, like OpenCL, have their own compilation pipeline.
Even when we use Python (which is interpreted), heavy computational libraries (like NumPy, CuPy, TensorFlow, and PyTorch) are themselves written in C/C++ and CUDA under the hood. Those parts have been compiled into efficient machine code. That is why, for example, NumPy can be fast; it uses compiled C code for array operations.
The role of a compiler in program execution:
You write source code (in C/C++/CUDA, etc.).
You run a compiler on that source code.
The compiler generates an executable (or a library) in machine code.
You run the executable, which directly uses the CPU/GPU hardware instructions.
With interpreted languages (Python, JavaScript, etc.), there is typically an interpreter or just-in-time (JIT) compiler that does translation on the fly, which is why pure Python is slower. However, Python libraries get speed by using compilers for the heavy lifting (e.g. compiling extension modules in C or using JIT compilers like Numba for numeric code).
Why do we care about compilers in a GPU training course?#
If you write custom CUDA kernels or C++ extensions for GPUs, you’ll be using compilers to build those. Even to install some GPU libraries, you might need a compatible compiler. For instance, to compile a PyTorch extension, you need a specific version of MSVC or gcc that matches the one used to build PyTorch. Tools like Spack (discussed earlier) help manage different compilers. HPC often requires using the right compiler for the right job to get maximum performance or compatibility with libraries. Understanding that code needs to be compiled and which compiler to use is important when troubleshooting. For example, if your code isn’t utilising the GPU, it might be because you didn’t compile it with CUDA or the correct flags.
Summary#
A compiler turns human-readable code into machine-efficient code. In HPC/GPU contexts, using the right compiler and compiler “flags” can significantly affect performance. It’s also why installing GPU software can be complex – the software might need to be compiled from source to match your system’s GPUs and libraries.
Bringing it all together#
CPU vs GPU: CPU = versatile, few cores, great for sequential or logic-heavy tasks. GPU = specialised, many cores, great for parallel numeric tasks.
Collaboration: In a typical GPU-accelerated program, the CPU and GPU work together. The CPU runs the overall program and offloads compute-intensive parts to the GPU. Data is passed back and forth. Getting this balance right is key to good performance.
Compilers: They ensure both CPU and GPU code is translated to run efficiently on the hardware. As a developer or user, you often rely on compilers indirectly when you use optimised libraries or when you build software from source on an HPC system.