Data Publishing#
Author: Christopher Tibbs (GitHub: ctibbs, ORCID: 0000-0002-3651-6573).
Reviewer: Dorothea Seiler Vellame (GitHub: dorotheavellame).
License: Creative Commons Attribution-ShareAlike 4.0 International license (CC BY-SA 4.0).
Course Objectives#
This short course will help you to:
Understand what data publishing is and why it is important to share research data.
Identify the steps to take to publish your research data.
What is data publishing and why is it important?#
Data Publishing is the process of sharing data so that it can be discovered, accessed, and reused by others. This process of sharing data is important, not only because it is a requirement of research institutions (including the University of Exeter) and external research funders, it also benefits the entire research community and wider society. Sharing data helps to maintain research integrity and enables validation of results. By publishing your data, you can increase your research profile leading to an increase in citations, and it can also lead to potential new research collaborations.
Preparing data for sharing#
The first step to publishing your data is preparing your data to be shared. This will be easier to do if you have been managing the data throughout the project, as you would already have all of your data organised and documented.
You need to determine if the data can be shared. It is crucial that you check if there are any reasons why the data may not be able to be shared (e.g., ethical, legal, or commercial reasons) and that you confirm that you are permitted to share the data. If you are unsure whether you can share your data or not, speak with your collaborators, or supervisor, or check your research ethics review if applicable. You can also speak to the University’s Research Ethics and Governance team for more information on managing research ethics, or the Exeter Innovation team to check for any commercialisation concerns.
If the data can be shared, then you need to decide whether they can be shared publicly or if you will require any access restrictions. Either way, if the data can be shared, it is important that the data are documented so that they are useable and others can understand them, and that the data are in formats that are open and accessible. Sharing data that are well documented and accessible helps others understand and reuse the data more easily, and it also reduces the number of queries you may receive asking you to explain the data.
For more help on how to organise and manage your data, see the Data Organisation: Best Practice short course.
How to determine which data repository to use#
The best way to publish your research data is to ensure that the data are FAIR. FAIR data are Findable, Accessible, Interoperable, and Reusable (find out more information about FAIR in the FAIR (meta)data short course, and the best way to make your data FAIR is to deposit the data, alongside the corresponding metadata, into a reputable research data repository.
There are many research data repositories available, and it can be difficult to determine which is the best repository to use for your data. Here are some questions to consider when trying to decide which data repository is a suitable long-term home for your data:
What type of data does the repository accept and what is its subject focus? Does this align with the type of data you wish to deposit?
Is the repository recommended by your funder or journal?
Will the repository provide enough metadata to enable your data to be discovered and cited by other researchers?
Will the repository issue your data with a unique persistent identifier?
Will the repository ensure that confidential/personal data are secured if that is required?
Is the repository established and well-funded, so that you can be confident it will still be in operation in ten years?
You can also use the registry of research data repositories, re3data, to find suitable repositories for your research discipline.
If a discipline-specific repository exists, you should use that to publish your data e.g., raw sequencing reads should be deposited with the Sequence Read Archive. However, if no such repository exisits, you can always use a generalist multi-disciplinary repository such as Zenodo or Figshare, or even the University of Exeter’s institutional repository, Open Research Exeter (ORE).
Keep in mind that some research funders require data to be deposited in a specific repository e.g., NERC (Natural Environment Research Council) support 5 data centres to manage the long-term preservation of environmental data produced as a result of NERC-funded research, while ESRC (Economic and Social Research Council) support the UK Data Service for ESRC-funded research data.
Licensing data#
In addition to depositing your data into a data repository, it is also important that you assign a reuse licence to your data. A licence makes it clear how others can reuse your data, and the Creative Commons licences are convenient ways of licensing your data.
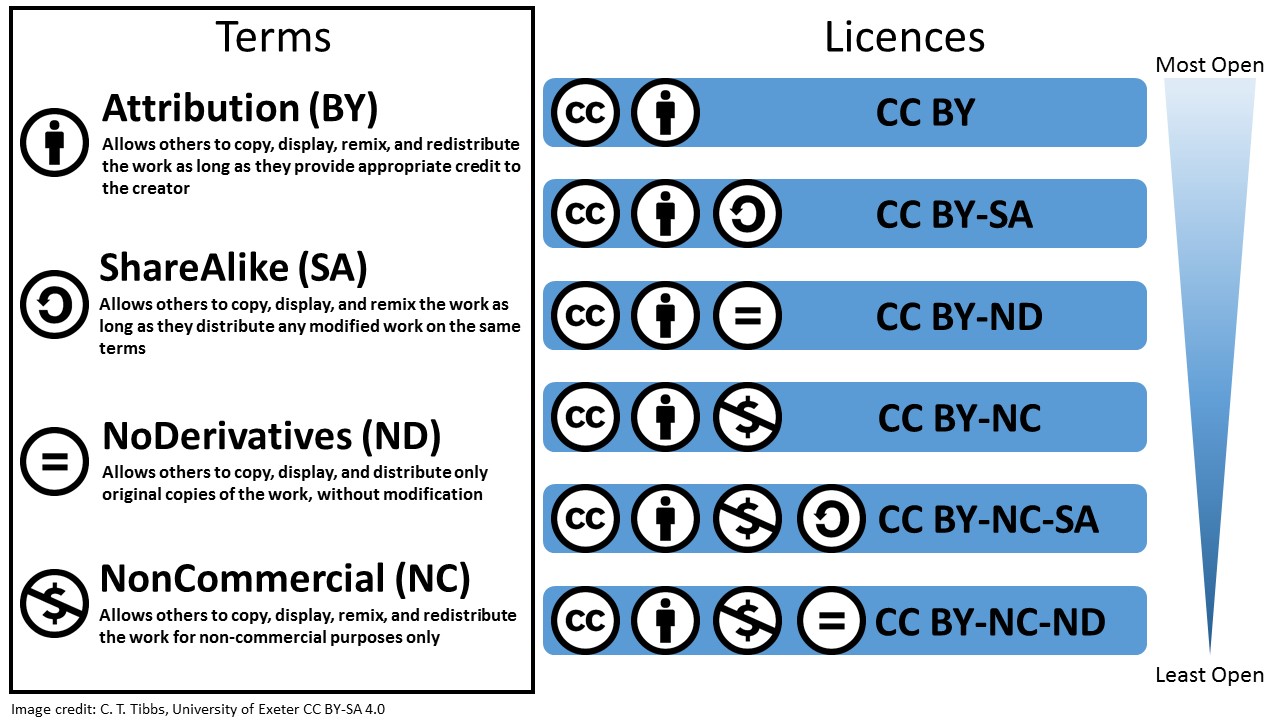
The Creative Commons licences cover a range of openness, from the most open CC BY licence, which allows others to reuse your data in any way as long as they acknowledge you as the creator, to the most restrictive CC BY-NC-ND licence, which allows others to reuse your data only in an unadapted form and for non-commercial purposes, as long as attribution is given to you as the creator. This range of openness ensures that you can select an appropriate licence to meet your requirements.
You can usually select the licence for your dataset when you upload your dataset to a repository.
Before licensing your data, it is very important to remember that if you plan to commercialise your data, then you should speak to the Exeter Innovation team before sharing your data.
Assigning a persistent identifier to your data#
Once your data have been prepared and licensed, they can be shared, but to effectively share research data, you also need a unique persistent identifier. A persistent identifier is simply a long-lasting identifier that is unique to a specific resource, and this enables the resource to be identified and cited.
You have probably already come across a persistent identifier. For example, Digital Object Identifiers (DOIs), are persistent identifiers that are commonly used in academia and all research publications are assigned a DOI by the publisher. Note that DOIs can also be assigned to other research outputs such as datasets and code.
It’s important to note that although a DOI is often displayed as a web address (e.g., http://doi.org/10.5255/UKDA-SN-9460-1), it is not a web address, it is an identifier that points to a web address. This distinction is important. For example, the DOI in the example above redirects to the web address: https://datacatalogue.ukdataservice.ac.uk/studies/study/9460. The repository that hosts that dataset is the UK Data Service, and this is reflected in the web address i.e., the ukdataservice.ac.uk portion of the web address. Therefore, if this repository was to change its name, it would likely change its web address to reflect such a change, and this would mean that the web address for the dataset would change (i.e., it is not persistent), however, the DOI would still point to the dataset (even after the name and web address change) and this is why a DOI is persistent. Therefore, whenever you are referring to a digital resource, it it best practice to use a persistent identifier for the resource if one exists, rather than simply using the web address.
In terms of getting a persistent identifier for your dataset, this is usually assigned when you deposit the data into a repository. If the repository that you are using does not assign a persistent identifier to your data, then you should find an alternative repository that does. Note that there are many different types of persistent identifiers available for digital resources such as DOIs, Handles, Accession numbers etc.
Data access/availability statements#
Repositories are generally searchable and indexed by search engines which makes any data you deposit to a repository highly discoverable. For datasets associated with a research publication, it is important to link the dataset to the publication and this can be done using a data access statement, also referred to as a data availability statement.
These statements should describe where and how any underlying research data may be accessed, ideally including a link to the data using a persistent identifier such as a DOI. The statement should also explain the terms on which the data are available. For example, are the data freely available for reuse, or must a data sharing agreement be formed before access is granted.
Here are some examples of data access statements that can be used in a given situation:
No new data generated e.g., “This study did not generate any new data.
Openly available data in a repository e.g., “The research data supporting this publication are openly available from the University of Exeter’s institutional repository at: https://doi.org/10.24378/exe.XXXXX”
Sensitive data with restricted access e.g., “Due to ethical concerns, the research data supporting this publication can only be made available to bona fide researchers subject to a data access agreement. Details of how to request access are available from the University of Exeter’s institutional repository at: https://doi.org/10.24378/exe.XXXXX”
The University of Exeter, along with the majority of research funders, requires a data access statement in all research publications.
Summary#
Hopefully it is now clear why you should share your research data and how to do so. Here is how you can publish your data in 4 simple steps:
1. Prepare your data for sharing: select, prepare, organise, and document your data, check any legal and/or ethical issues, and determine which level of access you will give to your data.
2. Select a repository: data should be deposited to a trusted community-recognised repository that specialises in the type of data you wish to deposit. Where no such repository exists, you should deposit the data to your institutional repository or another generalist multi-disciplinary repository.
3. Add a data access/availability statement to your publication: all publications should include a data access/availability statement, even if there are no associated data.
4. Link your dataset to your publication: add the DOI for the publication to the data record in the repository
Here is a good example of what a dataset deposited to a repository looks like: https://doi.org/10.5061/dryad.qnk98sfkg. You can see that this dataset has:
A descriptive title
Descriptive keywords
A DOI
A reuse licence
A link to the associated publication
A detailed readme file
A description of the methods
Open file formats
Activity#
Each data repository has their own interface, but they all capture the same essential information about the dataset you wish to upload (e.g., resource type, title, authors/creators, description, licence, date of publication, etc.). Here is a link to the guide to uploading a dataset to Zenodo, a generalist repository we discussed previously (https://help.zenodo.org/docs/get-started/quickstart/).
While this guide is helpful, it can be more intuitive to actually complete the process for yourself. Therefore, as an exercise, download this synthetic weather dataset (zenodo_dummy_dataset.zip), and go through the process of uploading it to the Zenodo sandbox.
The Zenodo sandbox is used for testing, and it allows you to go through the process of uploading a dataset to Zenodo. While the Zenodo sandbox is public, the DOIs assigned to datasets in the sandbox are not active and will not resolve.
Using the sandbox is a great way to become familiar with the process of publishing your data in Zenodo.
⚠️ Be sure you are uploading the dataset to the sandbox and not the production version of Zenodo. ⚠️